 Resources
Resources 
As businesses and researchers handle data sets of unprecedented size and complexity, the demand for high-speed data transfer is paramount. InfiniBand (IB) technology is a critical enabler of faster, more efficient data movement, and it is used in fields like high-performance computing (HPC), artificial intelligence (AI), and machine learning (ML).
Originally a niche solution, InfiniBand has evolved into a mainstream technology, powering data centers, research institutions, and tech giants. In this article, we comprehensively introduce InfiniBand technology, from its architecture and features to practical applications and comparisons with other networking options.
 Source: NVIDIA
Source: NVIDIA
If you’re looking to optimize your infrastructure for demanding workloads, CUDO Compute can provide the infrastructure and expertise to use InfiniBand technology effectively.
What is InfiniBand?
InfiniBand (IB) is a high-performance networking technology initially developed to address the limitations of traditional Ethernet and fiber channels, so it was created with high throughput, low latency, and scalability in mind.
InfiniBand offers incredibly high data transfer rates, supporting speeds of up to 400 Gbps and beyond, achieved through advancements like the Next Data Rate (NDR) specification, which enables 400 Gbps speeds per data lane.
Beyond the speed of InfiniBand, it also achieves ultra-low latency, often in the sub-microsecond range. The minimal delay is important for applications like high-performance computing and financial transactions, where even tiny delays can significantly impact overall performance.
InfiniBand is highly scalable and can connect thousands of nodes in a single cluster, making it ideal for large-scale deployments in high-performance computing, cloud data centers, and enterprise environments where massive interconnected systems are required.
For reliability, it incorporates features like redundant paths and failover mechanisms to ensure continuous operation even in hardware failures, guaranteeing data integrity and minimizing disruptions in critical applications.
Furthermore, InfiniBand incorporates quality of service (QoS) to guarantee smooth operation, allowing administrators to prioritize traffic and allocate bandwidth effectively, ensuring that high-priority tasks receive the necessary resources for optimal performance.
To understand how InfiniBand achieves such high performance, let's delve into its architecture.
InfiniBand architecture
InfiniBand’s architecture uses a switched fabric model to enable fast, low-latency communication between interconnected devices. Unlike traditional point-to-point networking, where devices connect via a single, direct line, the fabric architecture allows each node to communicate across multiple paths. This key distinction maximizes bandwidth and minimizes latency, ensuring efficient data flow even under heavy loads.
In practice, InfiniBand networks consist of a series of interconnected switches that route data packets between nodes along optimal paths. This multi-path capability enables redundancy and load balancing, ensuring high data availability and efficient handling of heavy data loads.
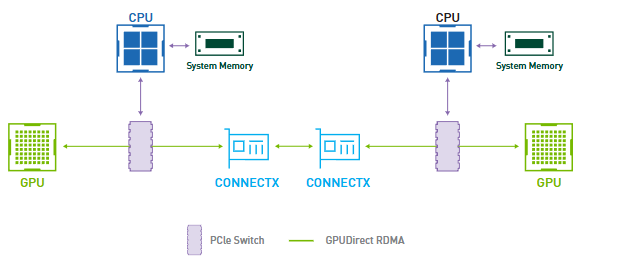
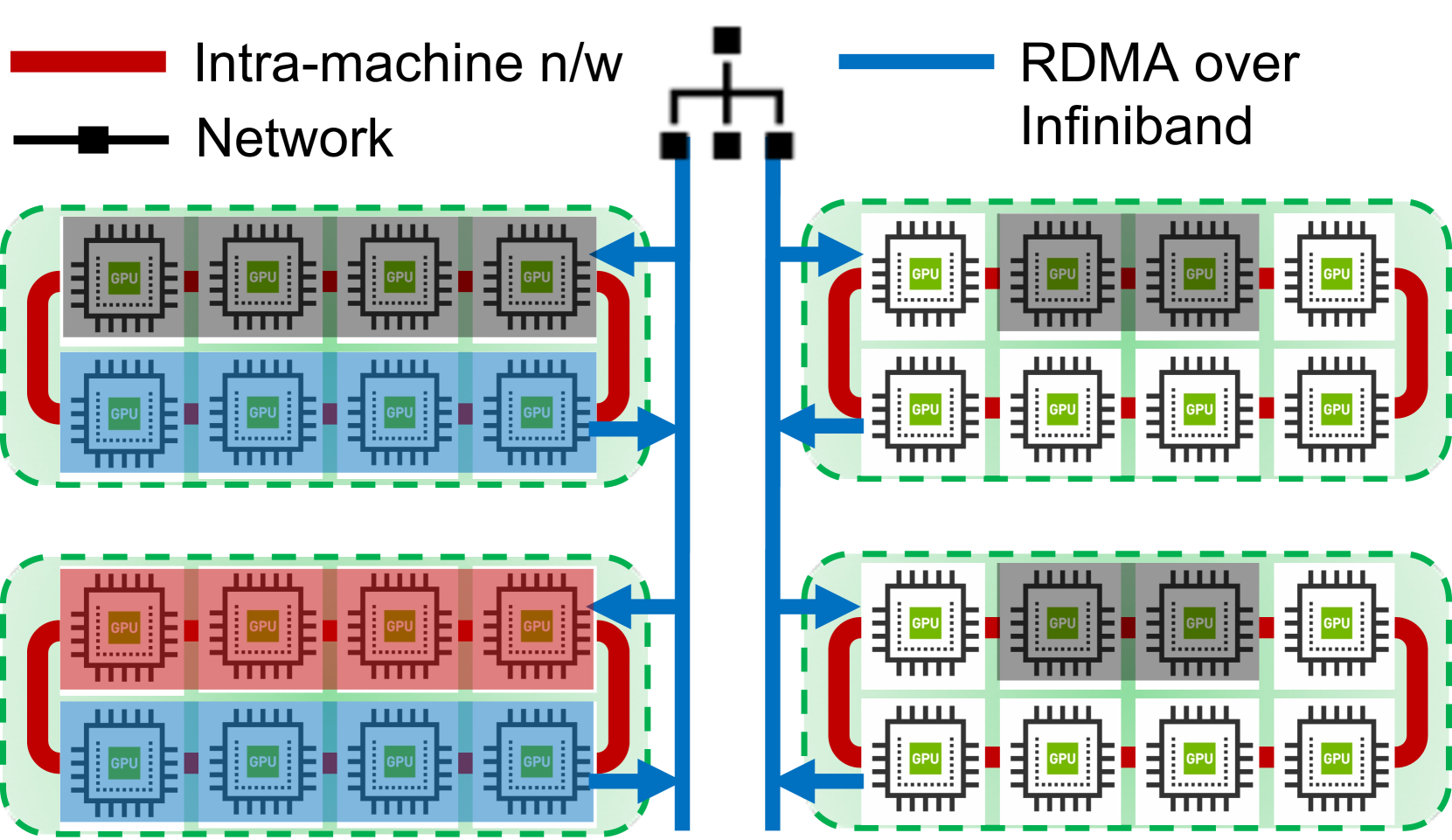
Furthermore, remote direct memory access (RDMA) in InfiniBand allows data to be transferred directly between memory locations across nodes without involving the CPU, further reducing latency and freeing CPU resources for other tasks.
The core components include:
 Source: NVIDIA
Source: NVIDIA
Host Channel Adapter (HCA): These network interface cards (NICs) connect servers to the InfiniBand fabric. HCAs handle data processing tasks directly, such as Remote Direct Memory Access (RDMA), offloading much of the workload from the CPU. This direct memory access feature is crucial for reducing latency and increasing transfer speed.
Target Channel Adapter (TCA): Primarily used to connect storage and other peripheral devices to the InfiniBand network. Like HCAs, TCAs manage data transfer at high speeds and low latency, ensuring that storage devices communicate effectively with compute nodes in HPC settings.
InfiniBand Switches: Switches are essential for directing data packets across the fabric. They provide multiple data paths to enable high-speed, low-latency communication across nodes. Advanced InfiniBand switches, like those from NVIDIA’s Quantum series, support speeds up to 400 Gbps (NDR) and help balance loads across the network.
Cables and Transceivers: These provide the physical connections between components in the fabric. Options include Direct Attach Copper (DAC) cables for short distances and Active Optical Cables (AOC) or fiber optic transceivers for longer distances. Each cable type supports different speed specifications, from 40 Gbps to 800 Gbps (XDR).
Links: Links are an integral part of the InfiniBand architecture and are considered essential components. In an InfiniBand network, links represent the physical and logical connections that transmit data between various nodes, such as servers, switches, and storage devices.
These links can be either electrical or optical, depending on the cabling type, and are available in different speeds and capacities, aligning with InfiniBand’s various data rate standards
InfiniBand links support multiple configurations, typically:
- 1X, 4X, and 12X configurations, indicating the number of lanes within the link. For example, a 4X link contains four lanes, significantly increasing data throughput compared to a 1X link.
- Speeds range from Single Data Rate (SDR) at 8 Gbps to advanced configurations like HDR (200 Gbps), NDR (400 Gbps), and even experimental XDR (up to 800 Gbps) for high-performance environments.
Subnet Manager: A software-based component that manages the InfiniBand fabric’s network topology, routing, and overall traffic. The subnet manager ensures that data follows optimal paths and adjusts dynamically to changing network conditions, preventing stoppages and maintaining network performance.
Gateways and Routers: Often used for integrating InfiniBand networks with Ethernet or Fibre Channel networks, gateways allow data transfer across different network types while preserving high throughput and low latency. Routers can also extend InfiniBand networks over larger areas, facilitating connectivity between different data center clusters.
InfiniBand’s architecture has become integral to high-performance environments, where the need for low latency and high bandwidth is paramount, particularly in data centers and HPC applications where bottlenecks can severely hinder performance.
Before we discuss how it works, let’s examine its use cases.
InfiniBand use cases
InfiniBand’s combination of high throughput, low latency, and scalability makes it ideal for various demanding applications in HPC, data centers, cloud computing, and beyond. Here are use cases of InfiniBand:
Common Use Cases
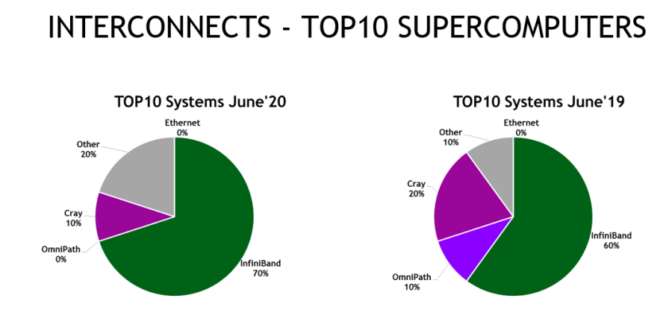
- High-Performance Computing (HPC): InfiniBand is everywhere in HPC environments, facilitating rapid data transfer between thousands of nodes. Its low-latency and RDMA features are especially beneficial in scientific simulations, financial modeling, and complex computational tasks.
 Source: NVIDIA
Source: NVIDIA
For example, 7 of the top 10 supercomputers use InfiniBand, including the most powerful systems in China, Europe, and the U.S.
Data Centers: Many data centers use InfiniBand to support large-scale data storage, network virtualization, and distributed computing. InfiniBand’s high throughput allows data centers to handle more significant data volumes.
Cloud Computing: In the cloud, InfiniBand enables efficient and fast inter-server communication, making it suitable for workloads with high data transfer demands, such as big data analytics and AI. InfiniBand is especially beneficial in GPU-based cloud computing, where latency impacts real-time processing.
Integration with GPU Computing and AI Workloads
InfiniBand has gained popularity in GPU-based workloads in recent years due to its RDMA and low-latency features. AI and ML models require massive data processing capabilities, which can be efficiently achieved with InfiniBand, particularly when working with NVIDIA GPUs, as the two technologies complement each other to accelerate data transfer.
InfiniBand also enables direct data sharing between GPUs, which is essential for distributed deep-learning tasks. The combined architecture allows for fast training and iteration in large-scale AI models, reducing time and resource consumption.
Read more on NVIDIA GPU architecture here: A beginner’s guide to NVIDIA GPUs.
InfiniBand in Storage and Virtualization
Storage systems can also benefit from InfiniBand, particularly in environments requiring quick access to vast amounts of data. InfiniBand allows virtualized workloads to communicate efficiently for virtualization, eliminating traditional issues associated with hypervisor layers and improving overall performance.
While initially designed for high-performance computing, InfiniBand has expanded into various applications, including cloud computing, artificial intelligence, and storage networking. Its ability to handle demanding workloads quickly and efficiently has made it a key technology for modern data centers.
Next, let’s discuss how InfiniBand works.
How InfiniBand Works
To grasp the capabilities of InfiniBand, it’s essential to understand its underlying architecture and operational protocols. InfiniBand uses a protocol stack designed for high-speed, reliable communication in data-intensive environments.
The InfiniBand protocol stack
The InfiniBand protocol stack consists of layers that manage communication between devices, each serving a distinct purpose to ensure reliable and efficient data transmission. These include:
- Physical Layer: Defines the hardware aspects, including cables, connectors, and signaling rates, to facilitate high-speed connections. For example, the physical layer supports link speed configurations, such as NDR and XDR.
- Link Layer: Manages data framing, flow control, and error detection, ensuring reliable transmission across individual links within the fabric. The link layer also enforces InfiniBand’s lossless networking by controlling buffer space to prevent data packet loss.
- Network Layer: Handles routing within subnets, assigning addresses, and optimizing data paths. This layer uses Local Identifiers (LIDs) assigned by a Subnet Manager to direct packets, ensuring efficient packet switching across nodes in the network.
- Transport Layer: Responsible for end-to-end data reliability and flow control, enabling InfiniBand’s use of RDMA technology.
- Upper Layers: The upper layer in InfiniBand is similar to the application layer in traditional networking stacks like OSI and TCP/IP, but it’s tailored to InfiniBand’s specific protocol and data handling needs. This layer serves as an interface for various high-level protocols and services that enable application-specific functions over InfiniBand networks.
The InfiniBand Upper Layer supports protocols and services such as:
- Small Computer System Interface (SCSI) for direct storage access,
- IP over InfiniBand (IPoIB), allowing IP data transfer across InfiniBand,
- Sockets Direct Protocol (SDP) for high-performance socket communication,
- Message Passing Interface (MPI) is essential for interprocess communication in HPC.
 Source: Paper
Source: Paper
These protocols enable InfiniBand to handle different types of data and connect with other network environments, similar to how the application layer facilitates user services in OSI. However, the Upper Layer also includes adaptations for InfiniBand’s high-speed, low-latency requirements, such as direct memory transfers through RDMA.
Step-by-step process of data transmission over infiniband
To illustrate the exact data transmission process over InfiniBand, let's break down each step from data preparation on the sender side to the successful delivery on the receiver side, including the internal mechanisms of packet formation, routing, and acknowledgment.
1. Data Preparation
- Data packetization: The sender application or process decides to transmit data to a remote node. InfiniBand prepares this data by dividing it into smaller chunks or packets, each fitting InfiniBand's maximum packet size (usually around 2 KB, although this can vary).
- Queue pair (QP) allocation: Each communication requires a Queue Pair (QP) consisting of a Send Queue and a Receive Queue. Both sender and receiver allocate QPs in advance. This QP pairing establishes a direct channel between nodes.
2. Building the Packet Header
- **Header Creation:**For each packet, InfiniBand constructs a header that includes:
- Global routing header (GRH): Provides routing information, especially if the packet traverses multiple subnets.
- Base transport header (BTH): Contains fields like the Operation Code (opcode), Queue Pair Number (QPN), and Packet Sequence Number (PSN), essential for managing packet flow and sequencing.
- Packet sequence number (PSN): Assigns a unique sequence number to each packet for tracking, ordering, and reassembly.
- CRC check: A checksum is computed and added to the header for error-checking purposes.
3. Initiating the transmission (RDMA write/read)
- Verb Execution: InfiniBand uses verbs (commands) to initiate transmission, with common verbs being RDMA Write (for sending data) or RDMA Read (for requesting data from a remote memory).
- RDMA write/read Operation:
- For RDMA Write, the sender places the data directly into a specified memory location on the receiver's side.
- For RDMA Read, the receiver directly retrieves data from the sender’s memory location.
- This memory access bypasses the CPU, reducing latency and offloading CPU resources.
4. Routing and packet transmission
- Switch fabric routing: InfiniBand’s switched fabric topology routes the packets through intermediate switches. The GRH in the header directs the packet's path to the destination node, even across different subnets if needed.
- Flow control and priority queueing: If the network is congested, InfiniBand’s built-in flow control mechanisms regulate packet flow, adjusting transmission speed to prevent packet loss. Additionally, packets are prioritized based on their QoS, ensuring high-priority data moves faster.
5. Receiving the packet at the destination
- Packet reception and queue processing: The receiving node’s Network Interface Card (NIC) reads incoming packets and directs them to the appropriate Receive Queue of the designated Queue Pair.
- Sequencing with PSN: As packets arrive, the receiving node uses the PSN in each packet’s header to verify the correct order.
- Acknowledgement and retransmission: For reliable communication, InfiniBand’s protocol uses acknowledgement (ACK) packets. Upon receiving a packet, the receiver sends an ACK for successful delivery. If a packet is missing or corrupted (detected via CRC), the sender is requested to retransmit the packet.
6. Data reassembly
- Reassembling rackets: Once the receiver receives all packets in the correct sequence, it reassembles them based on their PSNs, reconstructing the original data.
- Placement into application memory: The reconstructed data is then placed into the application’s memory space or the location specified by the RDMA operation, ready for use by the application.
7. End of transmission
- Completion queue notification: Both sender and receiver nodes use Completion Queues (CQs) to track the status of data transmissions. Once a transmission completes (either through all data being sent and acknowledged or via reassembly at the destination), a completion event is posted to the CQ, informing the application of successful data delivery.
Comparison with other networking technologies
InfiniBand isn’t the only technology available for networking in high-performance environments. Ethernet and Fibre Channel are other commonly used networking technologies that often serve as alternatives to InfiniBand. Here’s a comparative analysis:
InfiniBand vs. Ethernet
- Latency: InfiniBand generally provides much lower latency than Ethernet. While Ethernet is fast and widely used, even the latest 100 Gbps Ethernet technologies can’t match InfiniBand’s sub-microsecond latency.
- Throughput: InfiniBand offers higher throughput than Ethernet, with capabilities extending to 400 Gbps in some implementations.
- Scalability: While Ethernet is highly scalable, InfiniBand’s architecture is more tailored to large-scale compute clusters and data center environments, enabling it to maintain low latency even with increased node counts.
- Cost: Ethernet has a cost advantage due to its widespread adoption, making it more affordable for general networking. InfiniBand’s hardware and infrastructure costs can be higher but are justified in environments where performance outweighs cost considerations.
InfiniBand vs. Fibre Channel
- Purpose and Use Case: Fibre Channel is primarily used for storage area networks (SANs), designed to offer high-speed, reliable data transfer specifically for storage. InfiniBand, by contrast, is more versatile, handling both compute and storage networking.
- Performance: While Fibre Channel offers low latency and high reliability, it generally does not match InfiniBand’s latency and throughput capabilities, making it less suitable for high-performance computing.
- Flexibility: InfiniBand’s RDMA capabilities and protocol flexibility make it adaptable to various applications, from AI training to data center networking. Fibre Channel, on the other hand, is primarily focused on SANs and does not offer the same flexibility.
| Feature | InfiniBand | Ethernet | Fibre Channel |
|---|---|---|---|
| Primary Use | High-performance computing (HPC), high-bandwidth, low-latency applications | General purpose networking, connecting devices in LANs and WANs | Storage area networks (SANs) connecting servers to storage devices |
| Data Transfer Rate | Up to 400 Gbps and beyond (NDR) | Up to 400 Gbps (400GbE) and beyond | Up to 128 Gbps (Gen 7) |
| Latency | Extremely low (nanoseconds) | Relatively higher latency (microseconds) | Low latency, but typically higher than InfiniBand |
| Protocol | Uses its own specialized protocol with RDMA (Remote Direct Memory Access) | Primarily uses TCP/IP but also supports RDMA over Converged Ethernet (RoCE) | Uses its own specialized protocol optimized for storage communication |
| Topology | Switched fabric | Switched or shared media | Switched fabric |
| Cost | Generally higher than Ethernet | Generally lower than InfiniBand and Fibre Channel | Generally higher than Ethernet |
| Scalability | Highly scalable, designed for large clusters | Scalable, but can have limitations in very large, high-performance environments | Scalable, but typically used for smaller networks than InfiniBand |
| Advantages | Highest bandwidth and lowest latency, ideal for demanding applications | Versatile, widely adopted, cost-effective | Reliable, mature technology specifically designed for storage networking |
| Disadvantages | Higher cost, less widely adopted than Ethernet | Higher latency can be a bottleneck for some applications | Limited bandwidth compared to InfiniBand, not as versatile as Ethernet |
Conclusion
InfiniBand meets the rigorous demands of high-performance computing, data centers, and AI training and inference tasks. Its high throughput, low latency, and RDMA capabilities offer unique advantages, especially in environments where performance is paramount.
If you need InfiniBand's speed and low latency for your HPC and AI tasks, CUDO Compute offers the latestNVIDIA GPUs equipped with InfiniBand, like the NVIDIA H200. CUDO Compute provides the resources and support to ensure optimal performance, scalability, and efficiency in your data center or cloud environment. Get started now!
