 Resources
Resources 
Striking the right balance between performance and cost is crucial when selecting a GPU for deep learning and high-performance computing (HPC) tasks. The NVIDIA RTX A6000 may be an excellent choice for budget-conscious HPC professionals.
The A6000 is a high-performance GPU built on the NVIDIA Ampere architecture and designed to handle memory-intensive tasks across various applications. While it is similar to the NVIDIA RTX A5000 we discussed in our last article, some key details differentiate them.
In this article, we will discuss the A6000's specifications, price, and use cases. We will also address common questions to help you determine if the A6000 is the right hardware to power your workload.
NVIDIA A6000 specification
Like the A5000, the NVIDIA A6000 is also built on the GA102 architecture, which is a part of NVIDIA's Ampere GPU lineup. We have previously discussed the GA10x architecture in detail and its optimization for ray tracing, AI acceleration, and high-performance computing. Let us focus on the A6000’s capabilities specifically.
The A6000 includes 10,752 CUDA cores for general-purpose parallel computing, 336 third-generation Tensor Cores for AI acceleration, and 84 second-generation RT Cores for real-time ray tracing.
 Source: NVIDIA
Source: NVIDIA
One of the better features of the A6000 is double-speed processing for single-precision floating-point (FP32) operations, coupled with improved power efficiency over the A5000, achieving 38.71 TFLOPS in FP32 performance, whereas the A5000 achieves 27.77 TFLOPS. This improvement in F32 operation directly translates to substantial performance boosts in graphics and simulation workflows, such as complex 3D CAD and CAE projects.
The NVIDIA RTX A6000's second-generation RT Cores offer up to twice the throughput of the first-generation RT Cores, significantly enhancing real-time ray tracing performance. This improvement allows concurrent ray tracing, shading, and denoising, which is good for photorealistic rendering in movie production, architectural design evaluations, and virtual prototyping. Moreover, the second-generation RT Cores accelerate ray-traced motion blur, leading to faster and more visually accurate results.
The NVIDIA RTX A6000 features third-generation Tensor Cores that introduce the new Tensor Float 32 (TF32) precision, allowing up to 5X the training throughput compared to the Turing-based GPUs (such as the Quadro RTX 6000 and RTX 8000), significantly accelerating AI and data science model training without needing any code modifications. The TF32 precision mode is designed to handle single-precision convolution and matrix-multiply operations more efficiently, providing substantial performance improvements for deep-learning tasks.
With ultra-fast 48GB GDDR6 memory, scalable up to 96 GB with NVLink, you can gain the necessary memory capacity to work with massive datasets and demanding workloads, such as data science and simulation. The A6000 features increased GPU-to-GPU interconnect bandwidth, creating a single scalable memory space to tackle larger datasets and accelerate graphics and compute workloads.
| Specification | Details |
|---|---|
| GPU Memory | 48 GB GDDR6 |
| Memory Interface | 384-bit |
| Memory Bandwidth | 768 GB/s |
| Error-correcting Code (ECC) | Yes |
| NVIDIA Ampere architecture-based CUDA Cores | 10,752 |
| NVIDIA third-generation Tensor Cores | 336 |
| NVIDIA second-generation RT Cores | 84 |
| Single-precision Performance | 38.7 TFLOPS |
| RT Core Performance | 75.6 TFLOPS |
| Tensor Performance | 309.7 TFLOPS |
| NVIDIA NVLink | Connects two NVIDIA RTX A6000 GPUs |
| NVIDIA NVLink Bandwidth | 112.5 GB/s (bidirectional) |
| System Interface | PCI Express 4.0 x16 |
| Power Consumption | Total board power: 300 W |
| Thermal Solution | Active |
| Form Factor | 4.4" H x 10.5" L, dual slot, full height |
| Display Connectors | 4x DisplayPort 1.4a |
| Max Simultaneous Displays | 4x 4096 x 2160 @ 120 Hz, 4x 5120 x 2880 @ 60 Hz, 2x 7680 x 4320 @ 60 Hz |
| Power Connector | 1x 8-pin CPU |
| Encode/Decode Engines | 1x encode, 2x decode (+AV1 decode) |
| VR Ready | Yes |
| vGPU Software Support | NVIDIA vPC/vApps, NVIDIA RTX Virtual Workstation, NVIDIA Virtual Compute Server |
| vGPU Profiles Supported | 1 GB, 2 GB, 3 GB, 6 GB, 8 GB, 8 GB, 12 GB, 16 GB, 24 GB, 48 GB |
| Graphics APIs | DirectX 12.07, Shader Model 5.17, OpenGL 4.68, Vulkan 1.1 |
| Compute APIs | CUDA, DirectCompute, OpenCL |
It also supports NVIDIA virtual GPU (vGPU) software, which transforms a single workstation into multiple high-performance virtual workstation instances. This enables remote users to share resources.
NVIDIA A6000 deep learning performance benchmarks
The NVIDIA A6000 GPU demonstrates significant performance enhancements for deep learning applications. A Louisiana State University study focused on training a modified DenseNet121 model on a cat and dog image dataset benchmarked NVIDIA A6000s against a CPU, evaluating key metrics such as utilization, memory access, temperature, power usage, training time, throughput, and accuracy. Here is a breakdown of the experimental setup:

Experimental Setup
- Operating System: Windows 11 x64
- Manufacturer: Dell
- CPU: Intel(R) Xeon(R) Gold 6256
- GPU: NVIDIA A6000 (2 units)
- Total GPU Memory: 48 GB per GPU
- Clock Rate: 3.60 GHz
- Total RAM: 512 GB
- Total Disk: 8 TB SSD
Here is the model and dataset setup:
Model and Dataset
- Model: DenseNet121 (with modifications to the final layers for binary classification)
- Dataset: Cat and dog images from Kaggle
- Training Set: 8005 images
- Testing Set: 2023 images
- Classes: 2 (cat and dog)
- Training Epochs: 20
- Optimizer: Adam
- Loss Function: Cross-entropy
- Batch Sizes: 64 and 128
- Learning Rates: 0.003 and 0.03
Training deep learning models involves processing large amounts of data through complex computations, which can be time-consuming. The comparison between training on a CPU and an NVIDIA A6000 GPU highlights the performance improvements it offers.

Training Time Comparison
- Training on CPU:
- DenseNet121 model trained for 20 epochs: 13 hours
- Inference time per image: 5 seconds
Training the DenseNet121 model on a CPU is slow because CPUs are designed for general-purpose computing and typically have fewer cores optimized for sequential processing. This results in longer training times as the CPU processes each batch of data sequentially and handles the extensive computations involved in neural network training.
- Training on A6000:
- DenseNet121 model trained for 20 epochs with batch size 64: 2 hours
- DenseNet121 model trained for 20 epochs with batch size 128: 1 hour and 15 minutes
- Inference time per image: 2-3 seconds
GPUs, on the other hand, are specifically designed for parallel processing. They have thousands of cores that can handle many tasks simultaneously, making them ideal for the highly parallel nature of neural network computations. This parallelism allows the GPU to process larger batches of data at once, significantly reducing the overall training time.
Impact of Batch Size on Training Time
- Batch Size 64:
- When the batch size is 64, the training time on the A6000 GPU is reduced to 2 hours. This batch size uses the parallel processing power of the GPU, but there is still room for optimization.
- Batch Size 128:
- Increasing the batch size to 128 reduces the training time to 1 hour and 15 minutes. Larger batch sizes mean more data is processed in each iteration, which better utilizes the GPU’s parallel processing capabilities, thus speeding up the training process even more.
Inference Time
- Inference on CPU: 5 seconds per image
- Inference on GPU: 2-3 seconds per image
Inference is the process of making predictions with a trained model. The GPU also significantly speeds up inference time. While the CPU takes around 5 seconds to process each image, the GPU can do it in 2-3 seconds. This improvement is critical in real-time applications where quick predictions are essential.
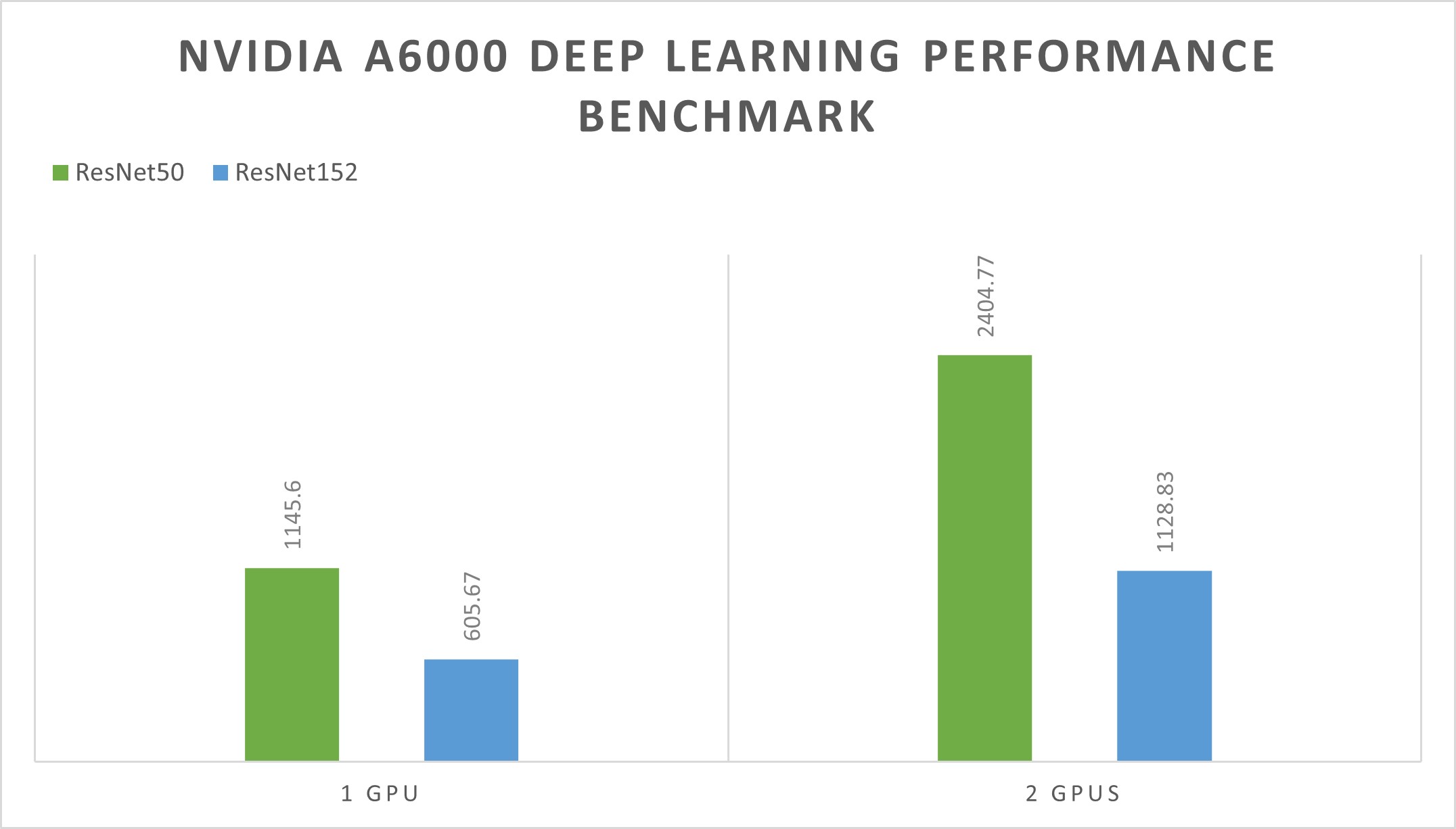
Further to this point, a comparison of the A6000 with other Ampere GPUs corroborates the fact that the A6000 demonstrates exceptional performance in deep learning tasks, as shown in the table below:
| Neural Network | 1 GPU | 2 GPUs | Batch Size |
|---|---|---|---|
| ResNet50 | 1145.6 | 2404.77 | 1024 |
| ResNet152 | 605.67 | 1128.83 | 512 |
Note: The numbers in the table represent throughput in images per second. Higher values indicate faster performance.
As seen from the table, using the ResNet50 network, the RTX A6000 processes over 1,100 images per second with a single GPU and scales efficiently to nearly 2,400 images per second with two GPUs.
Even with the more complex ResNet152 network, the RTX A6000 performs well, processing over 600 images per second with a single GPU and scaling to over 1,100 images per second with two. The ability to maintain high processing rates while increasing complexity and scaling across multiple GPUs showcases the RTX A6000's impressive deep-learning capabilities.
The substantial reduction in training time, improved inference time, and ability to handle large batch sizes and complex models demonstrate how the NVIDIA A6000 can speed up deep learning tasks. This efficiency accelerates developing and deploying deep learning models and enhances their real-time performance in production environments.
Pricing
The price of the NVIDIA RTX A6000 can fluctuate depending on the retailer, region, and current market conditions. Due to high demand and the ongoing global chip shortage, availability may be limited. It's recommended to compare prices across different vendors and sign up for stock notifications to secure your purchase.
You can access the NVIDIA RTX A6000 on CUDO Compute. As of the time of writing, the A6000 is available on demand at competitive rates, starting from:
$0.79 per hour
$577.10 per month
Compared to the newer Hopper GPUs, this cloud-based solution offers a cost-effective alternative for professionals who require access to high-performance GPU resources.
Other use cases and applications of the NVIDIA A6000
Other use cases where the A6000 can be applied include:

Gaming
While primarily designed for professional applications, the A6000 also excels in high-end gaming:
- 4K Resolution and Ray Tracing: Gamers can enjoy exceptional performance at 4K resolution with smooth gameplay and enhanced visuals. The A6000’s second-generation RT Cores provide superior ray tracing capabilities, delivering realistic lighting, shadows, and reflections. Popular games like Call of Duty and Battlefield V run seamlessly at maximum settings.
- DLSS Technology: The A6000 supports NVIDIA's DLSS technology, which uses AI to upscale lower resolutions to 4K. This results in better frame rates and image quality, making gaming more immersive and visually stunning without compromising performance.
Professional Applications
The A6000 offers substantial improvements for various professional fields:
- Architecture, Engineering, and Media Production: The A6000’s large memory capacity and processing power enable faster rendering and more complex simulations. Software such as Blender, SolidWorks, and DaVinci Resolve benefit significantly from the A6000’s capabilities, allowing for improved performance in high-resolution video editing, 3D rendering, and scientific simulations.
- Handling Large Datasets: The ability to manage large datasets and complex models makes the A6000 an invaluable tool for professionals. Its performance in high-resolution video editing, 3D rendering, and scientific simulations is unparalleled, providing efficiency and speed for demanding projects.
VR and AR
The A6000 is well-suited for virtual and augmented reality applications:
- Smooth Performance: The A6000’s high frame rates and low latency ensure a seamless VR and AR experience. This is crucial for developers working on immersive experiences and simulations, enhancing the realism and interactivity of these applications.
- Training Simulations and Medical Applications: The A6000’s performance in VR and AR makes it suitable for training simulations, medical applications, and virtual prototyping. Its powerful rendering capabilities support the creation of highly detailed and interactive virtual environments.
Additional Applications
- Scientific Research: The A6000 is ideal for scientific research requiring high computational power and large memory capacity. It supports complex physics, chemistry, and biology simulations, enabling researchers to visualize and analyze data more effectively.
- Artificial Intelligence and Deep Learning: With its third-generation Tensor Cores and support for TF32 precision, the A6000 excels in AI and deep learning tasks. It accelerates model training and inference, making it a powerful tool for AI researchers and developers.
- Content Creation: The A6000 supports content creation applications, providing the performance needed for tasks such as video editing, animation, and graphic design. Its advanced features enable creators to work efficiently with high-resolution content and complex effects.
Follow our blog for in-depth analyses, comparisons, and performance insights on GPUs and CPUs that can accelerate your work.
